Dataset Composition¶
DafnyBench is sourced across three different places, consisting of 782 programs of ground truth
The benchmark consists of 782 ground truth Dafny programs totaling approximately 53,000 lines of code. These programs come from three sources:
GitHub scrape: 556 programs (de-duplicated from ~15,000 files down to ~5,000 unique programs)
Clover benchmark: 62 textbook-style programs
Dafny-synthesis: 164 programs translated from the MBPP (Mostly Basic Python Problems) dataset
The Fill-Hints Task¶
DafnyBench’s core evaluation task to fill hints. To generate the task, they start with a verified Dafny program that compiles without errors and then remove all assert and invariant statements (the “hints” that help the verifier). The task for the LLM is to take the stripped program[1] and fill the hints back in. If the resulting program verifies successfully with Dafny, then the LLM solved that sample.
The solution should also check for “cheating” by including {:verify false} or assume false.
That’s just a loop with extra steps¶
That’s a loop
Morty
No its not, its an agent. It has a language model send code to a compiler and when the compiler reports an error message, it goes back into the language model.
Rick
That’s just a loop with extra steps
Morty
The two greatest practitioners of english are Shakespeare and Trump. Each of them can add words and phrases to the language, but unlike when you and I add words and phrases to the language, when Shakespeare and Trump do it their words and phrases actually get adopted. The win condition for that sort of thing is when people forget that you’re the one who coined the phrase. The Rick and Morty writers have had (arguably, to my knowledge) one such victory, which is “with extra steps”.
Most of this book is approximately as conceptually profound as “just a loop with extra steps”.
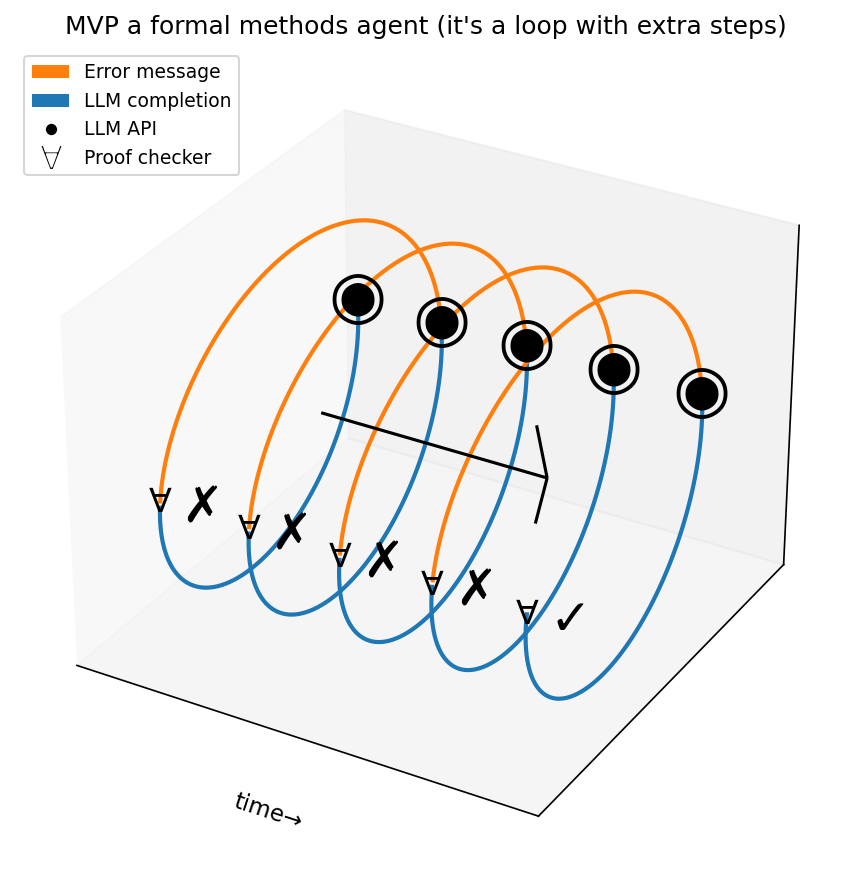
Figure 1:MVP: the loop between LLM (◉) and a verifier (∀)
The key scaffolding strategy in the DafnyBench baselines is iterative refinement with error feedback. Models get up to 10 attempts per program:
Model submits its first attempt at filling in hints
If it fails to verify, the model receives the actual Dafny compiler error message
Model tries again, taking the error message into account
This continues for up to 10 attempts, with early stopping upon success
The minimal agent architecture is this loop scaffold. The Dafny verifier, like any other compiler, provides an error message which is a rich signal of how to correct one’s mistakes.
In what follows, we will replicate those baselines using a modern agentdev framework, one which did not exist when the DafnyBench authors shipped their papers.
DafnyBench does not mark where the hints were removed. There are no
/* TODO */comments or placeholder lines. Human proof engineers, deep in the verification mines, inhaling the dust and fumes, do not necessarily know where they need a hint.